


Para responder a esse desafio, pesquisadores da Universidade do Texas em Austin desenvolveram o que eles acreditam ser o primeiro método de “Desaprendizagem de máquina” aplicado à IA generativa baseada em imagem. Este método oferece a capacidade de olhar sob o capô e bloquear ativamente e remover quaisquer imagens violentas ou obras protegidas por direitos autorais sem perder o resto das informações no modelo. O estudo foi publicado no servidor de pré-impressão arXiv.
“Quando você treina esses modelos em conjuntos de dados tão massivos, você deve incluir alguns dados que são indesejáveis”, disse Radu Marculescu, professor do Departamento de Engenharia Elétrica e de Engenharia de Computação da Cockrell School of Chandra e um dos líderes do projeto.
Anteriormente, a única maneira de remover conteúdo problemático era descartar tudo, começar de novo, retirar manualmente todos esses dados e treinar novamente o modelo. Nossa abordagem oferece a oportunidade de fazer isso sem ter que treinar o modelo a partir do zero.”
Os modelos de IA generativos são treinados principalmente com dados na internet por causa da quantidade incomparável de informações que ela contém. Mas também contém grandes quantidades de dados que são protegidos por direitos autorais, além de informações pessoais e conteúdo inadequado.
Ressaltando esse problema, o The New York Times processou recentemente a OpenAI, fabricante do ChatGPT, argumentando que a empresa de IA usou ilegalmente seus artigos como dados de treinamento para ajudar seus chatbots a gerar conteúdo.
“Se quisermos tornar os modelos de IA generativos úteis para fins comerciais, este é um passo que precisamos construir, a capacidade de garantir que não estamos infringindo as leis de direitos autorais ou abusando de informações pessoais ou usando conteúdo prejudicial”, disse Guihong Li, assistente de pesquisa de pós-graduação no laboratório de Marculescu, que trabalhou no projeto como estagiário do JPMorgan Chase e finalizou na UT.
Os modelos de imagem para imagem são o foco principal desta pesquisa. Eles pegam uma imagem de entrada e a transformam – como criar um esboço, mudar uma cena específica e mais – com base em um determinado contexto ou instrução.
Este novo algoritmo de desaprendizagem de máquina fornece a capacidade de um modelo de aprendizado de máquina de “esquecer” ou remover o conteúdo se ele for sinalizado por qualquer motivo, sem a necessidade de reciclagem do modelo a partir do zero. As equipes humanas lidam com a moderação e remoção de conteúdo, fornecendo uma verificação extra do modelo e capacidade de responder ao feedback do usuário.
Crédito da imagem: arXiv (2024). DOI: 10.48550/arxiv.2402.00351
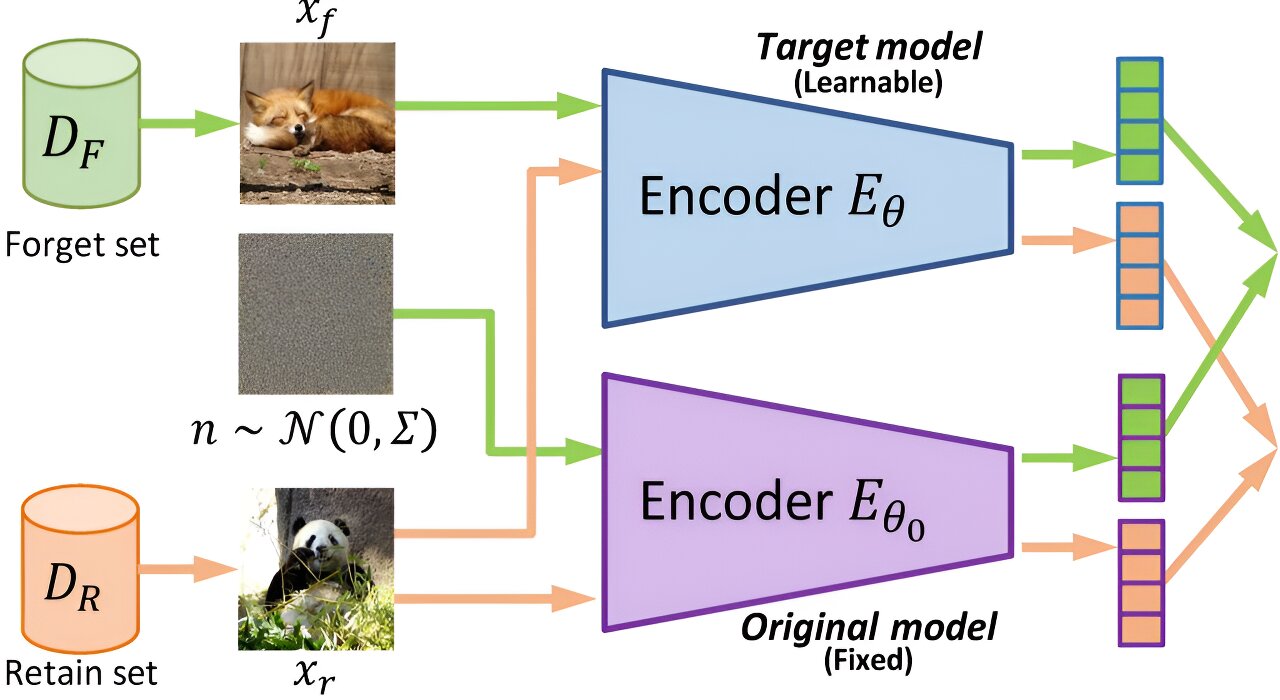
O desaprendizagem de máquina é um ramo em evolução do campo que
tem sido aplicado principalmente a modelos de classificação.
Esses modelos são treinados para classificar os dados em diferentes
categorias, como se uma imagem mostra um cão ou um gato.
A aplicação de desaprendizagem de máquina a modelos generativos é “relativamente inexplorada”, escrevem os pesquisadores no artigo, especialmente quando se trata de imagens.
Mais informações: Guihong Li et al, Máquina Desaprendizagem |
0 resposta